python3 爬补天公益src 厂商名称和url

获取厂商的地址:
注意: cookie 是已经登陆的cookie
import json
import requests
import time
from bs4 import BeautifulSoup
def spider():
'''
:return:
'''
headers = {
'Host': 'butian.360.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'Referer': 'http://butian.360.cn/Reward/pub//Message/send',
'Cookie': '这里是已经登陆的cookie!!!!!',
'Connection': 'keep-alive'
}
for i in range(1,149):
data={
'p': i,
'token': ''
}
time.sleep(3)
res = requests.post('http://butian.360.cn/Reward/pub/Message/send', data=data,headers=headers,timeout=(4,20))
allResult = {}
allResult = json.loads(res.text)
currentPage = str(allResult['data']['current'])
currentNum = str(len(allResult['data']['list']))
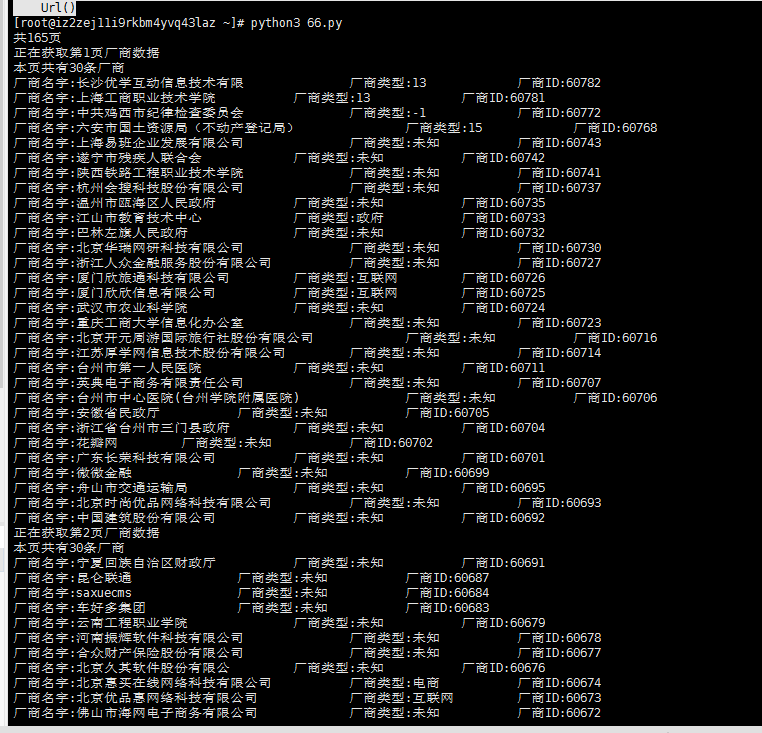
print('正在获取第' + currentPage + '页厂商数据')
print('本页共有' + currentNum + '条厂商')
for num in range(int(currentNum)):
print('厂商名字:'+allResult['data']['list'][int(num)]['company_name']+'\t\t厂商类型:'+allResult\
['data']['list'][int(num)]['industry']+'\t\t厂商ID:'+allResult['data']['list'][int(num)]['company_id'])
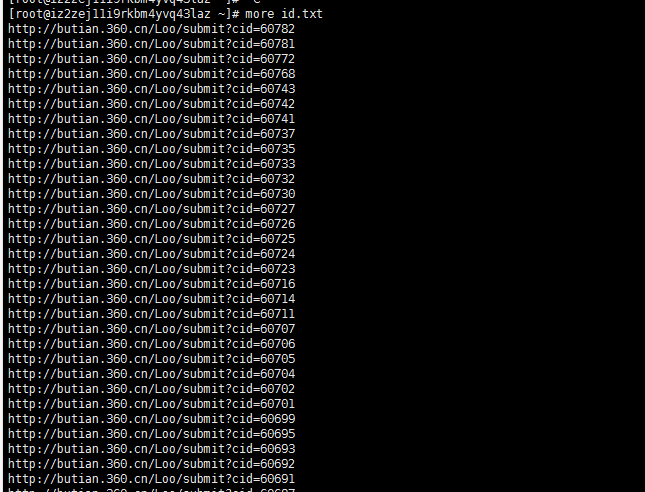
base='http://butian.360.cn/Loo/submit?cid='
with open('id.txt','a') as f:
f.write(base+allResult['data']['list'][int(num)]['company_id']+'\n')
if __name__=='__main__':
data = {
's': '1',
'p': '1',
'token': ''
}
res = requests.post('http://butian.360.cn/Reward/pub/Message/send', data=data)
allResult = {}
allResult = json.loads(res.text)
allPages = str(allResult['data']['count'])
print('共' + allPages + '页')
spider()
如下:
执行完之后会有一个id.txt
查看一下
获取完之后, 我们在用另一个py 获取厂商的名字和厂商的URL
import json
import requests
import time
from bs4 import BeautifulSoup
def Url():
'''
遍历所有的ID
取得对应的域名
保存为target.txt
:return:
'''
headers={
'Host':'butian.360.cn',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'Referer':'http://butian.360.cn/Reward/pub',
'Cookie': '已经登陆的cookie!!!!',
'Connection':'keep-alive',
'Upgrade-Insecure-Requests': '1',
'Cache-Control':'max-age=0'
}
with open('id.txt','r') as f:
for target in f.readlines():
target=target.strip()
getUrl=requests.get(target,headers=headers,timeout=(4,20))
result=getUrl.text
info=BeautifulSoup(result)
url=info.find(name='input',attrs={"name":"host"})
name = info.find(name='input', attrs={"name": "company_name"})
lastUrl=url.attrs['value']
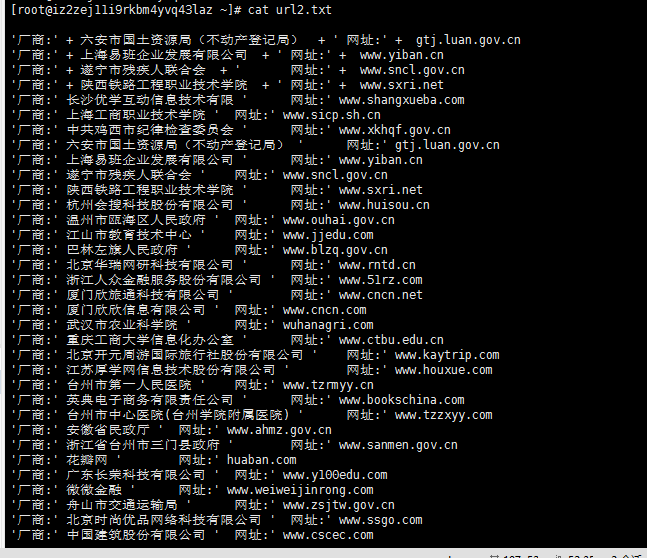
print('厂商:' + name.attrs['value'] + '\t网址:' + url.attrs['value'])
url2="'厂商:' %s '\t网址:' %s "%(name.attrs['value'],url.attrs['value'])
with open('url2.txt','a') as liang:
liang.write(url2+'\n')
with open('target.txt','a') as t:
t.write(lastUrl+'\n')
time.sleep(3)
print('The target is right!')
Url()
执行结果
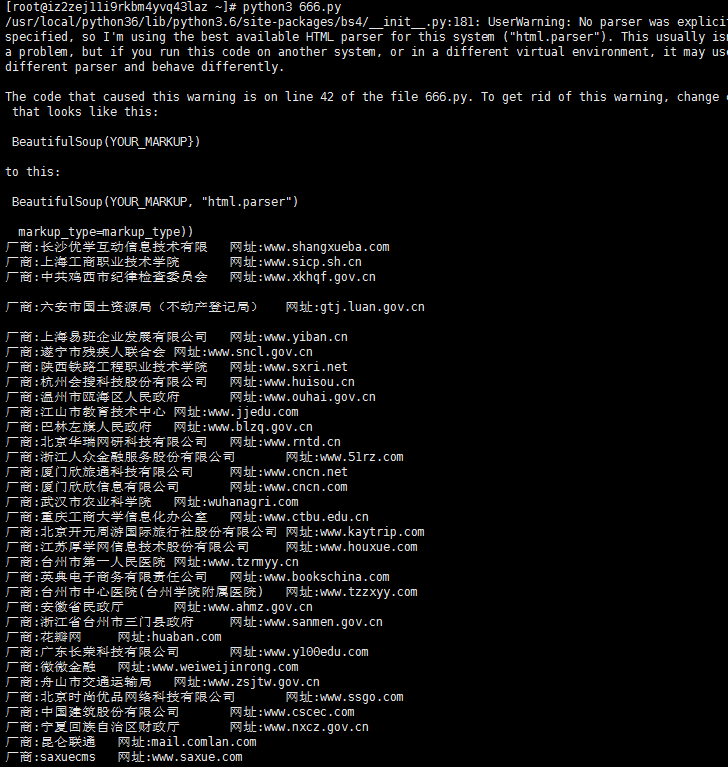
执行完之后会有两个文件一个是url2.txt 一个是target.txt
url2.txt 是记录着是厂商和url
target.txt 是只记录url地址
完整的一个py如下:
import json
import requests
import time
from bs4 import BeautifulSoup
def spider():
'''
:return:
'''
headers = {
'Host': 'butian.360.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'Referer': 'http://butian.360.cn/Reward/pub//Message/send',
'Cookie': '这里是已经登陆的cookie!!!!!',
'Connection': 'keep-alive'
}
for i in range(1,149):
data={
'p': i,
'token': ''
}
time.sleep(3)
res = requests.post('http://butian.360.cn/Reward/pub/Message/send', data=data,headers=headers,timeout=(4,20))
allResult = {}
allResult = json.loads(res.text)
currentPage = str(allResult['data']['current'])
currentNum = str(len(allResult['data']['list']))
print('正在获取第' + currentPage + '页厂商数据')
print('本页共有' + currentNum + '条厂商')
for num in range(int(currentNum)):
print('厂商名字:'+allResult['data']['list'][int(num)]['company_name']+'\t\t厂商类型:'+allResult\
['data']['list'][int(num)]['industry']+'\t\t厂商ID:'+allResult['data']['list'][int(num)]['company_id'])
base='http://butian.360.cn/Loo/submit?cid='
with open('id.txt','a') as f:
f.write(base+allResult['data']['list'][int(num)]['company_id']+'\n')
def Url():
'''
遍历所有的ID
取得对应的域名
保存为target.txt
:return:
'''
headers={
'Host':'butian.360.cn',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'Referer':'http://butian.360.cn/Reward/pub',
'Cookie': '已经登陆的cookie!!!! ',
'Connection':'keep-alive',
'Upgrade-Insecure-Requests': '1',
'Cache-Control':'max-age=0'
}
with open('id.txt','r') as f:
for target in f.readlines():
target=target.strip()
getUrl=requests.get(target,headers=headers,timeout=(4,20))
result=getUrl.text
info=BeautifulSoup(result)
url=info.find(name='input',attrs={"name":"host"})
name = info.find(name='input', attrs={"name": "company_name"})
lastUrl=url.attrs['value']
print('厂商:' + name.attrs['value'] + '\t网址:' + url.attrs['value'])
url2="'厂商:' %s '\t网址:' %s "%(name.attrs['value'],url.attrs['value'])
with open('url2.txt','a') as liang:
liang.write(url2+'\n')
with open('target.txt','a') as t:
t.write(lastUrl+'\n')
time.sleep(3)
print('The target is right!')
if __name__=='__main__':
data = {
's': '1',
'p': '1',
'token': ''
}
res = requests.post('http://butian.360.cn/Reward/pub/Message/send', data=data)
allResult = {}
allResult = json.loads(res.text)
allPages = str(allResult['data']['count'])
print('共' + allPages + '页')
spider()
Url()



video buzz du moment 2017
2018年6月3日 下午3:13
Certains blogs proposent l’échange d’articles.
roy
2018年7月14日 上午2:45
不知道为什么一直报错
lastUrl=url.attrs[‘value’]
AttributeError: ‘NoneType’ object has no attribute ‘attrs’
print("")
2018年7月14日 上午10:29
你没有设置URL吧