PHP 词法分析/语法分析
仓库代码
https://github.com/aaPanel/aaWAF/tree/main/php_engine
PHP执行流程
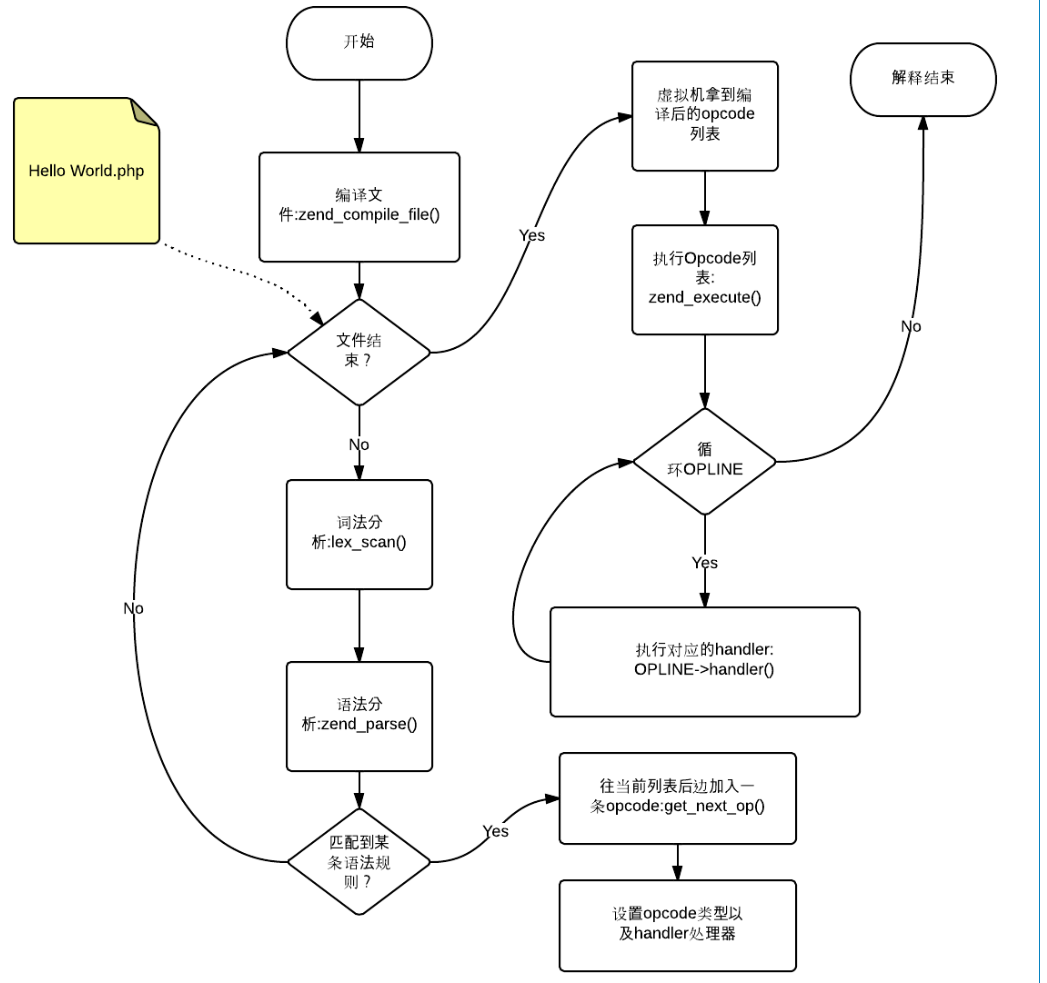
参考:
https://github.com/php/php-src/blob/master/Zend/zend_language_scanner.l
https://github.com/php/php-src/blob/master/Zend/zend_language_parser.y
一、词法分析
1.1 Lexer结构体 以及实例化
// Lexer 结构体定义了PHP词法分析器的核心数据结构
type Lexer struct {
data []byte // 待分析的源代码字节数组
phpVersion *version.Version // PHP版本信息,用于兼容性处理
errHandlerFunc func(*errors.Error) // 错误处理函数
p, pe, cs int // p: 当前位置, pe: 数据结束位置, cs: 当前状态
ts, te, act int // ts: token开始位置, te: token结束位置, act: 当前动作
stack []int // 状态栈,用于处理嵌套结构
top int // 栈顶指针
heredocLabel []byte // 当前heredoc标签
tokenPool *token.Pool // token对象池,优化内存分配
positionPool *position.Pool // 位置对象池,优化内存分配
newLines NewLines // 跟踪源码中的新行位置
}
// NewLexer 创建并初始化一个新的词法分析器实例
func NewLexer(data []byte, config conf.Config) *Lexer {
lex := &Lexer{
data: data, // 设置源代码
phpVersion: config.Version, // 设置PHP版本
errHandlerFunc: config.ErrorHandlerFunc, // 设置错误处理函数
pe: len(data), // 设置数据结束位置
stack: make([]int, 0), // 初始化状态栈
// 初始化对象池和行号追踪
tokenPool: token.NewPool(position.DefaultBlockSize),
positionPool: position.NewPool(token.DefaultBlockSize),
newLines: NewLines{make([]int, 0, 128)}, // 预分配空间以提高性能
}
initLexer(lex) // 初始化词法分析器状态机
return lex
}
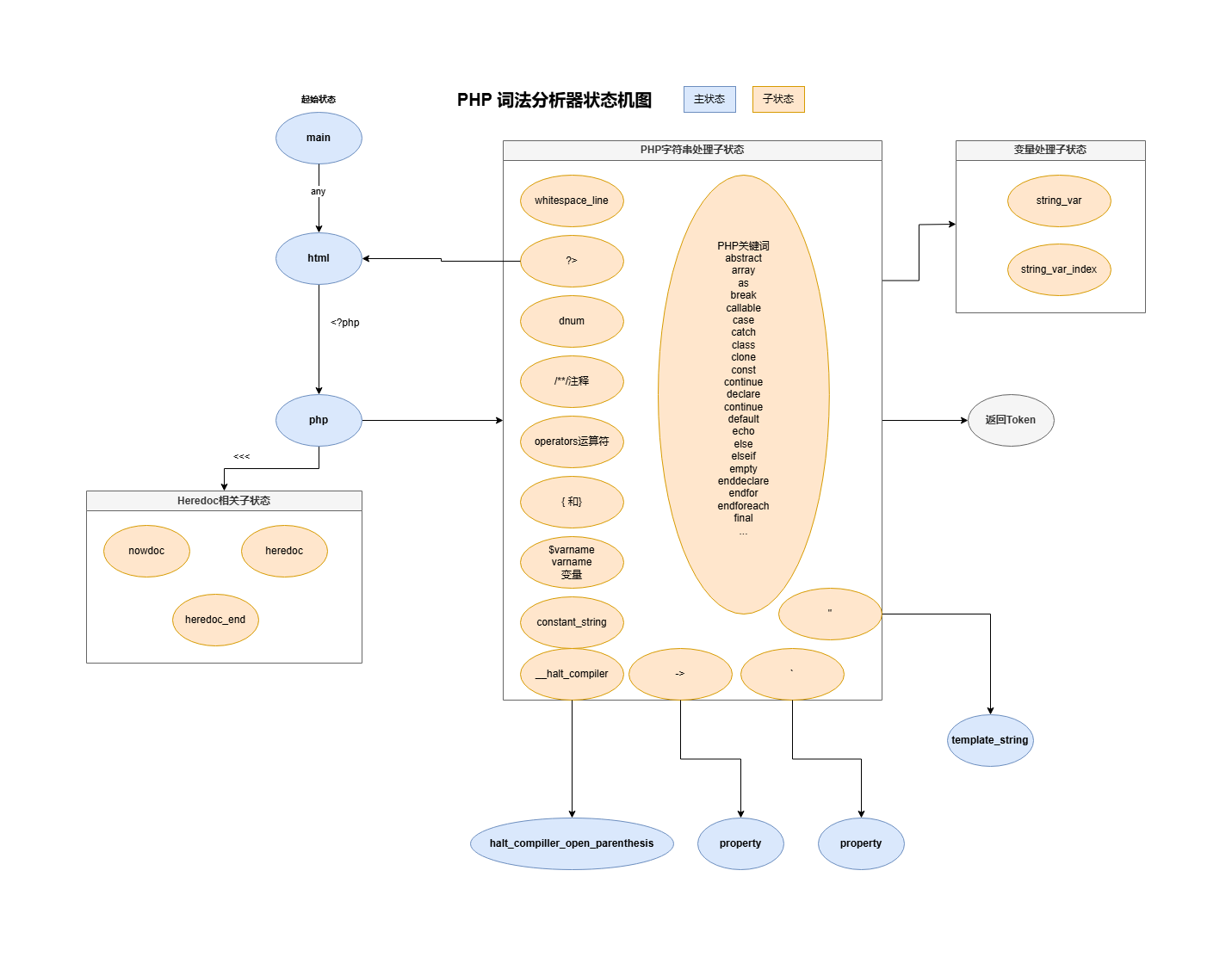
1.1 此法解析状态机
大概的一个状态机的图
1.2 解析一个简单的php文件
<?php phpinfo();?>
1.2.1 首先是进入到main的主状态
1.2.1 首先是进入到main的主状态
main := |*
any => {
fnext html; // 切换到html 状态
lex.ungetCnt(1) // 将刚读取的字符推回输入流
};
*|;
1.2.2 进入到html主状态
html := |*
'<?php'i ( [ \t] | newline ) => {
lex.ungetCnt(lex.te - lex.ts - 5) // 回退到空格这个地方。让下一个读取能获取到
lex.addFreeFloatingToken(tkn, token.T_OPEN_TAG, lex.ts, lex.ts+5)
fnext php;
};
进入到了php的主状态
1.2.3 空格返回
whitespace_line* => {lex.addFreeFloatingToken(tkn, token.T_WHITESPACE, lex.ts, lex.te)};
1.2.4 Phpinfo 返回
varname => { lex.setTokenPosition(tkn); tok = token.T_STRING; fbreak; };
1.2.5 ( 返回
operators => {
lex.setTokenPosition(tkn);
tok = token.ID(int(lex.data[lex.ts]));
fbreak;
};
1.2.6 ) 返回
operators => {
lex.setTokenPosition(tkn);
tok = token.ID(int(lex.data[lex.ts]));
fbreak;
};
1.2.6 ;?>
';' whitespace_line* '?>' newline? => {lex.setTokenPosition(tkn); tok = token.ID(int(';')); fnext html; fbreak;};
1.2.7 汇总
Value: T_OPEN_TAG vlue: <?php Value: T_WHITESPACE vlue: T_STRING phpinfo ID(40) ( ID(41) ) ID(59) ;?>
二、词法分析
输入的如下举例
src := []byte(` <?php phpinfo();?>`)
输入的Token为
T_INLINE_HTML vlu: T_STRING vlu: phpinfo ID(40) vlu: ( ID(41) vlu: ) ID(59) vlu: ;?> ID(0) vlu: ;?>
2.1 第一个T_INLINE_HTML
statement:
| T_INLINE_HTML
{
$$ = &ast.StmtInlineHtml{
Position: yylex.(*Parser).builder.NewTokenPosition($1),
InlineHtmlTkn: $1,
Value: $1.Value,
}
}
规约到top_statement
top_statement:
error
{
// error
$$ = nil
}
| statement
{
fmt.Println("规约到top_statement")
$$ = $1
}
规约到top_statement_list
top_statement_list:
top_statement_list top_statement
{
fmt.Println("规约到top_statement_list")
if $2 != nil {
$$ = append($1, $2)
}
}
| /* empty */
{
$$ = []ast.Vertex{}
}
;
2.2 T_STRING phpinfo
到namespace_name 节点
namespace_name:
T_STRING
{
fmt.Println("Identifier2:", $1.Value)
$$ = &ParserSeparatedList{
Items: []ast.Vertex{
&ast.NamePart{
Position: yylex.(*Parser).builder.NewTokenPosition($1),
StringTkn: $1,
Value: $1.Value,
},
},
}
}
2.3 ID(40) (
先规约后面操作
name:
namespace_name
{
fmt.Println("规约到name")
}
规约到name 之后读入(
function_call:
name argument_list
{
fmt.Println("规约到function_call")
$$ = &ast.ExprFunctionCall{
Position: yylex.(*Parser).builder.NewNodesPosition($1, $2),
Function: $1,
OpenParenthesisTkn: $2.(*ArgumentList).OpenParenthesisTkn,
Args: $2.(*ArgumentList).Arguments,
SeparatorTkns: $2.(*ArgumentList).SeparatorTkns,
CloseParenthesisTkn: $2.(*ArgumentList).CloseParenthesisTkn,
}
}
刚好符合argument_list 但是这里差了一个( 等待后续输入
argument_list:
'(' ')'
{
fmt.Println("argument_list1")
$$ = &ArgumentList{
Position: yylex.(*Parser).builder.NewTokensPosition($1, $2),
OpenParenthesisTkn: $1,
CloseParenthesisTkn: $2,
}
}
2.4 ID(41) )
这里就符合了argument_list
argument_list:
'(' ')'
{
fmt.Println("argument_list1")
$$ = &ArgumentList{
Position: yylex.(*Parser).builder.NewTokensPosition($1, $2),
OpenParenthesisTkn: $1,
CloseParenthesisTkn: $2,
}
}
规约到function_call
function_call:
name argument_list
{
xxx
}
规约到callable_variable
callable_variable:
| function_call
{
fmt.Println("function_call规约到callable_variable")
$$ = $1
}
2.5 ID(59) ;?>
先规约到variable
expr:
variable
{
$$ = $1
}
规约到expr
expr:
variable
{
fmt.Println("规约到expr")
$$ = $1
}
读入; 符合statement
statement:
| expr ';'
{
$$ = &ast.StmtExpression{
Position: yylex.(*Parser).builder.NewNodeTokenPosition($1, $2),
Expr: $1,
SemiColonTkn: $2,
}
}
规约到top_statement
top_statement:
error
{
// error
$$ = nil
}
| statement
{
fmt.Println("规约到top_statement")
$$ = $1
}
规约到top_statement_list
top_statement_list:
top_statement_list top_statement
{
fmt.Println("规约到top_statement_list")
if $2 != nil {
$$ = append($1, $2)
}
}
| /* empty */
{
$$ = []ast.Vertex{}
}
;
2.6 读入ID 0
先规约
start:
top_statement_list
{
xxx
}
这里符合start 的要求。这个语法通过

