SQL注入之语义分析
一、语义分析介绍
1.1 介绍
此次分析的语义分析模块使用的是 https://github.com/wallarm/libdetection
libdetection 原理是通过用户输入的字符串 使用词法提取的方式生成词法的Token 并标记好
当前Token的危险等级、和操作符,发送给语法分析, 再由语法分析进行提起符合预设的规则判断为攻击行为。
1.2 与正则、指纹库方案对比
|
名称
|
优点
|
缺点
|
|
语义分析
|
1.准确率高:深入理解 SQL 语句的语义,能准确识别复杂的注入模式,不易被绕过。例如对于利用编码、变形等手段隐藏的注入语句也有较好的检测效果。
2. 适应性强:可以适应不同类型的数据库和 SQL 语法,不局限于特定的规则。
3. 可检测复杂逻辑:能够检测包含复杂逻辑和嵌套结构的注入攻击,如多重条件组合、子查询注入等。
|
1.性能开销大:需要对 SQL 语句进行深度解析和语义理解,计算资源消耗大,处理速度相对较慢,在高并发场景下可能成为性能瓶颈。
|
|
正则表达式
|
1.实现简单:语法相对简单,易于编写和理解,开发成本低。可以快速实现基本的 SQL 注入检测规则。
|
1.规则维护困难:随着攻击手段的不断变化,需要不断更新和完善正则表达式规则,否则容易出现漏判。
|
|
Libinjection指纹库
|
1.轻量级:代码简洁,资源占用少,对系统性能影响小,适合在资源受限的环境中使用。
|
1.规则有限:预定义的规则可能无法覆盖所有的 SQL 注入场景,对于一些新型的攻击手段可能检测能力不足。
|
二、架构
2.1 框架图
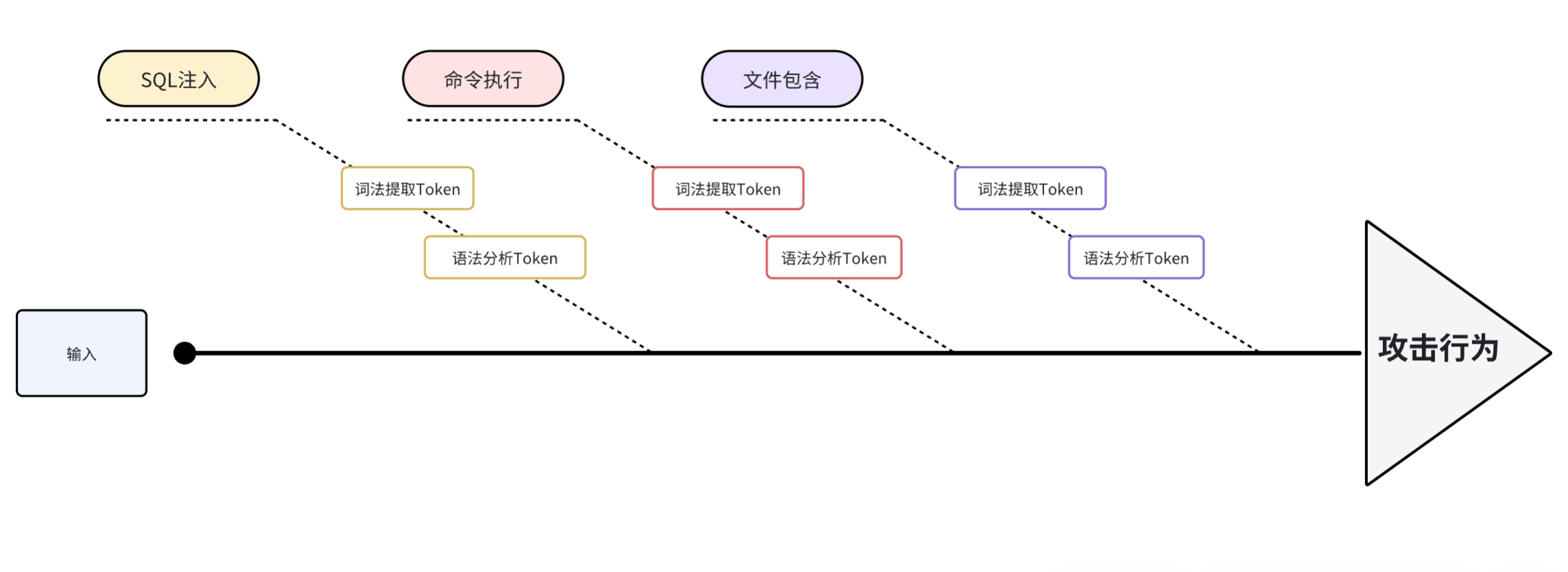
2.2 执行流程图
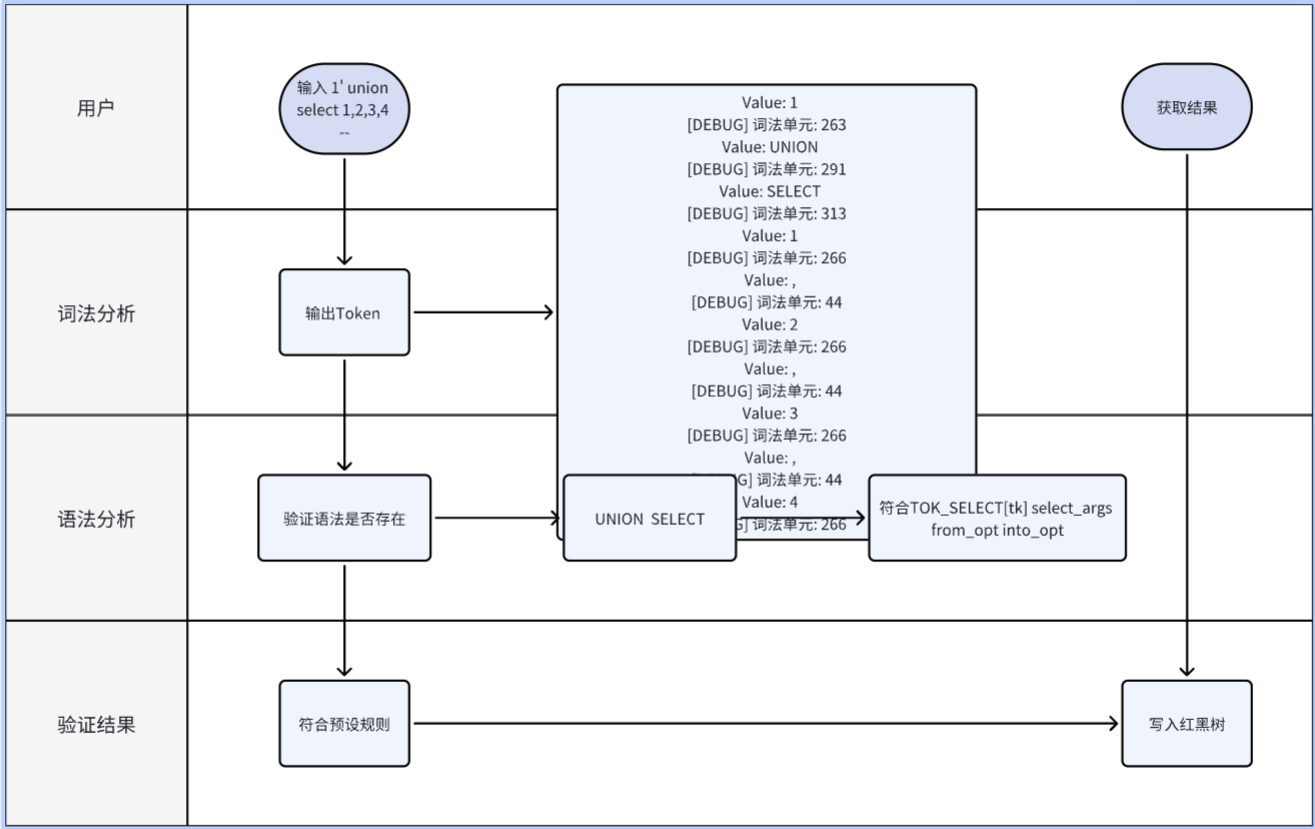
三、源码分析
3.1 处理的总流程图
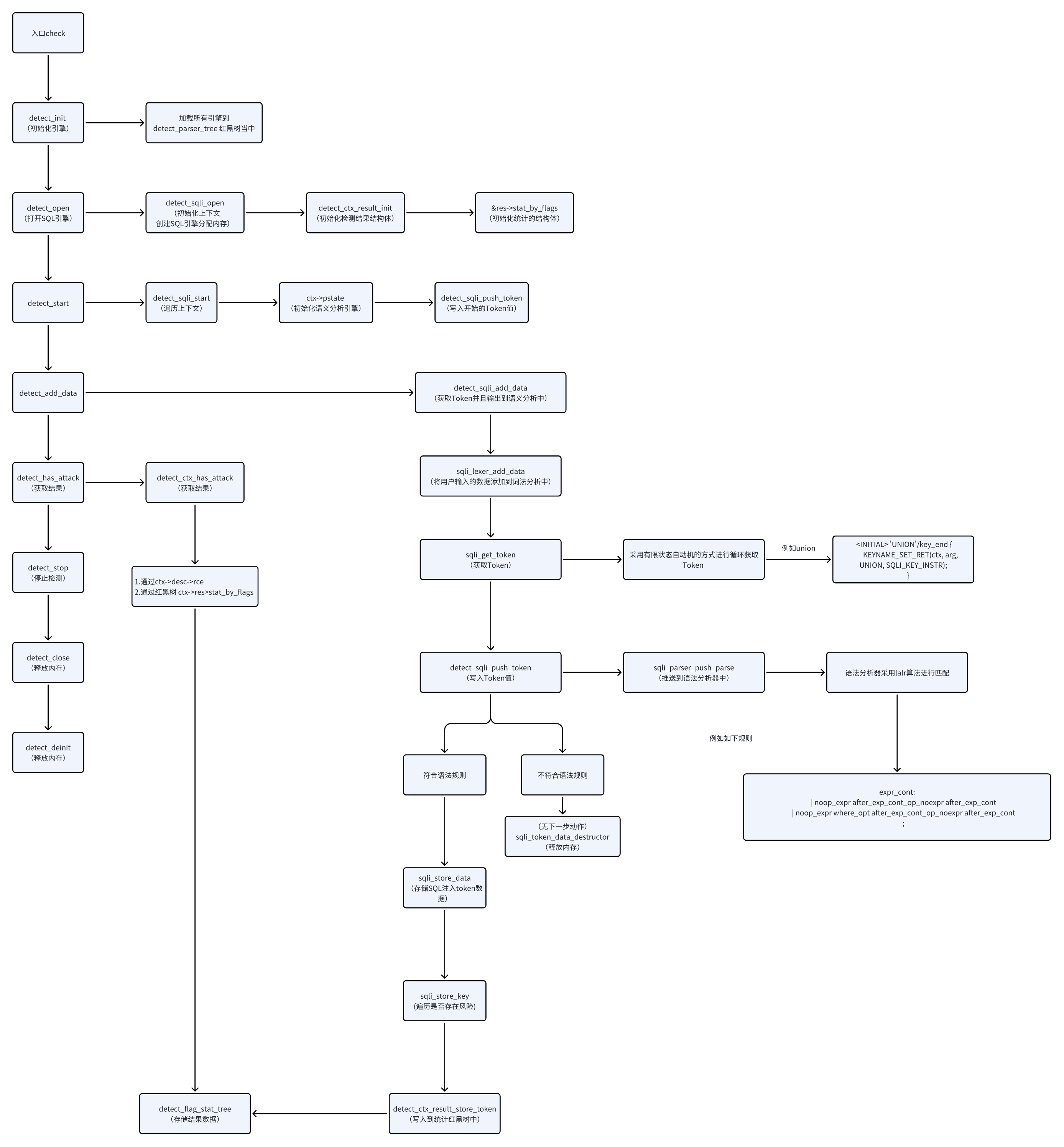
3.2 detect_init 初始化
初始化现有的所有的一个解析器模块
int
detect_parser_init(void)
{
int rc = 0;
// 初始化红黑树存储结构
RB_INIT(&detect_parsers);
// 顺序加载内置解析器模块
TRYLOAD(rc, detect_parser_sqli);
TRYLOAD(rc, detect_parser_pt);
TRYLOAD(rc, detect_parser_bash);
done:
// 任一模块加载失败时执行全局清理
if (rc) {
detect_parser_deinit();
}
return (rc);
}
例如:detect_parser_sqli
每个模块都是detect_parser 结构体
struct detect_parser detect_parser_sqli = {
.name = {CSTR_LEN("sqli")},
.open = detect_sqli_open,
.close = detect_sqli_close,
.start = detect_sqli_start,
.stop = detect_sqli_stop,
.add_data = detect_sqli_add_data,
};
// 模块的结构体
// 每个对象都是一个函数指针。这样就可以方便的使用入口函数调用模块内的函数
struct detect_parser {
struct detect_str name;
detect_parser_init_func init;
detect_parser_deinit_func deinit;
detect_parser_open_func open;
detect_parser_close_func close;
detect_parser_set_options_func set_options;
detect_parser_start_func start;
detect_parser_stop_func stop;
detect_parser_add_data_func add_data;
};
3.3 detect_open 初始化模块上下文
这里调用的是SQL 那么调用就是sql的detect_parser_open_func 函数指针 最终调用到detect_sqli_open
static struct detect *
// 创建并初始化SQL注入检测器实例
detect_sqli_open(struct detect_parser *parser)
{
// 初始化一个detect 结构体
struct detect *detect;
unsigned i;
//
detect = malloc(sizeof(*detect));
//初始化检测器基础结构,设置解析器指针
detect_instance_init(detect, parser);
// 设置上下文数量(对应枚举SQLI_CTX_LAST的值)
detect->nctx = SQLI_CTX_LAST;
// 为所有上下文分配内存
detect->ctxs = malloc(detect->nctx * sizeof(*detect->ctxs)); // 申请了6块 detect_ctx 指针内存的地址
for (i = 0; i < detect->nctx; i++) {
// 每个上下文地址都是detect_ctx 这个结构体指针
// detect_ctx 结构体包含了 detect_ctx_desc detect_ctx_result 这两个结构体
struct sqli_detect_ctx *ctx;
ctx = calloc(1, sizeof(*ctx));
ctx->base.desc = (struct detect_ctx_desc *)&sqli_ctxs[i].desc; // 这里例如第一个就是data
ctx->base.res = &ctx->res;
detect_ctx_result_init(ctx->base.res); // 初始化检测结果结构体
ctx->type = i;
ctx->ctxnum = i;
ctx->detect = detect; // 指向detect 结构体
ctx->var_start_with_num = sqli_ctxs[i].var_start_with_num; // 是否变量以数字开头
// 这里存储的是sqli_detect_ctx 结构体。
// 因为sqli_detect_ctx 中第一个成员就是detect_ctx 结构体 所以等价于detect_ctx
detect->ctxs[i] = (void *)ctx;
}
// 返回初始化好的检测器
return (detect);
}
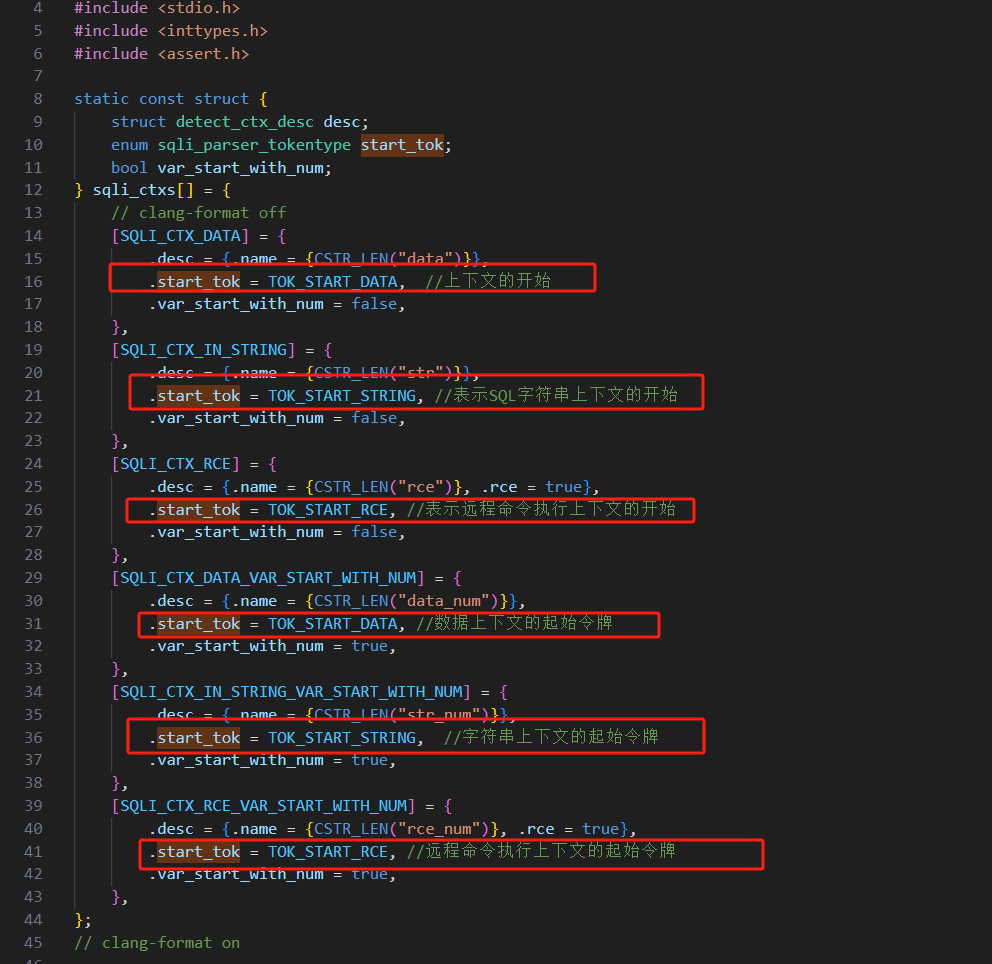
3.4 detect_start 给上下文变量赋值
内置了5种检测类型
static const struct {
struct detect_ctx_desc desc;
enum sqli_parser_tokentype start_tok;
bool var_start_with_num;
} sqli_ctxs[] = {
// clang-format off
[SQLI_CTX_DATA] = {
.desc = {.name = {CSTR_LEN("data")}},
.start_tok = TOK_START_DATA, //上下文的开始
.var_start_with_num = false,
},
[SQLI_CTX_IN_STRING] = {
.desc = {.name = {CSTR_LEN("str")}},
.start_tok = TOK_START_STRING, //表示SQL字符串上下文的开始
.var_start_with_num = false,
},
[SQLI_CTX_RCE] = {
.desc = {.name = {CSTR_LEN("rce")}, .rce = true},
.start_tok = TOK_START_RCE, //表示远程命令执行上下文的开始
.var_start_with_num = false,
},
[SQLI_CTX_DATA_VAR_START_WITH_NUM] = {
.desc = {.name = {CSTR_LEN("data_num")}},
.start_tok = TOK_START_DATA, //数据上下文的起始令牌
.var_start_with_num = true,
},
[SQLI_CTX_IN_STRING_VAR_START_WITH_NUM] = {
.desc = {.name = {CSTR_LEN("str_num")}},
.start_tok = TOK_START_STRING, //字符串上下文的起始令牌
.var_start_with_num = true,
},
[SQLI_CTX_RCE_VAR_START_WITH_NUM] = {
.desc = {.name = {CSTR_LEN("rce_num")}, .rce = true},
.start_tok = TOK_START_RCE, //远程命令执行上下文的起始令牌
.var_start_with_num = true,
},
};
detect_sqli_start 函数都会给每个上下文进行初始化。给这个上下文最开始的一个状态。
这里使用了detect_sqli_push_token 进行写入状态
static int
detect_sqli_start(struct detect *detect)
{
unsigned i;
// 遍历所有上下文
for (i = 0; i < detect->nctx; i++) {
struct sqli_detect_ctx *ctx = (void *)detect->ctxs[i];
// 如果当前上下文已经完成,则跳过
if (ctx->res.finished){
printf("ctx %u finished\n", i);
continue;
}
// yypstate_new
ctx->pstate = sqli_parser_pstate_new();
sqli_lexer_init(&ctx->lexer);
if (detect_sqli_push_token(ctx, sqli_ctxs[ctx->type].start_tok, NULL) != 0)
break;
}
return (0);
}
四、词法分析
re2c 代码如下
https://github.com/wallarm/libdetection/blob/master/lib/sqli/sqli_lexer.re2c
4.1 detect_add_data 添加Token到语法分析中
首先是通过sqli_get_token 来获取到上下文的的一个Token 那么这个Token 是怎么产生的。如下
static int
detect_sqli_add_data(struct detect *detect, const void *data, size_t siz, bool fin)
{
unsigned i;
union SQLI_PARSER_STYPE token_arg;
int rv = 0;
// 遍历所有上下文
for (i = 0; i < detect->nctx; i++) {
// 打印一下i对应的start_tok
printf("[DEBUG] 开始检测上下文: %u\n", i);
struct sqli_detect_ctx *ctx = (void *)detect->ctxs[i];
//
int token;
// 如果当前上下文的解析已经完成,则跳过该上下文
if (ctx->res.finished)
continue;
sqli_lexer_add_data(ctx, data, siz, fin);
do {
memset(&token_arg, 0, sizeof(token_arg)); // 清空token_arg结构体
token = sqli_get_token(ctx, &token_arg);
done:
return (rv);
}
4.2 Token 产生的过程
以用户输入1′ union select 1,2,3,4 — 为例子
ctx->lexer.instring 为true的状态下
最开始进入到词法分析中
<> {
// 检查是否在字符串处理模式
if (ctx->lexer.instring) {
// 如果在字符串中,设置为字符串处理状态
YYSETCONDITION(sqli_INSTRING);
arg->data.flags = SQLI_DATA_NOSTART;
detect_buf_init(&ctx->lexer.buf, MINBUFSIZ, MAXBUFSIZ);
goto sqli_INSTRING;
}
// 如果不在字符串中,设置为初始状态
YYSETCONDITION(sqli_INITIAL);
goto sqli_INITIAL;
}
4.2.1 处理1
那么会跳转到INSTRING 节点处理1
<INSTRING> "''"|'""'|'``' {
detect_buf_add_char(&ctx->lexer.buf, DETECT_RE2C_YYCURSOR(&ctx->lexer.re2c)[-1]);
goto sqli_INSTRING;
}
<INSTRING> ['"`] => INITIAL {
YYSETSTATE(-1);
printf("INSTRING\n");
RET_DATA(DATA, ctx, arg);
}
<INSTRING> ']' => INITIAL {
YYSETSTATE(-1);
RET_DATA(NAME, ctx, arg);
}
<INSTRING,SQUOTE,DQUOTE,BQUOTE,IQUOTE> [\x00] {
if (ctx->lexer.re2c.fin && ctx->lexer.re2c.tmp_data_in_use &&
ctx->lexer.re2c.pos >= ctx->lexer.re2c.tmp_data + ctx->lexer.re2c.tmp_data_siz) {
YYSETCONDITION(sqli_INITIAL);
DETECT_RE2C_YYCURSOR(&ctx->lexer.re2c)--;
arg->data.flags |= SQLI_DATA_NOEND;
YYSETSTATE(-1);
RET_DATA(DATA, ctx, arg);
}
detect_buf_add_char(&ctx->lexer.buf, DETECT_RE2C_YYCURSOR(&ctx->lexer.re2c)[-1]);
DETECT_RE2C_UNUSED_BEFORE(&ctx->lexer.re2c);
goto yy0;
}
<INSTRING,SQUOTE,DQUOTE,BQUOTE,IQUOTE> .|[\n] {
detect_buf_add_char(&ctx->lexer.buf, DETECT_RE2C_YYCURSOR(&ctx->lexer.re2c)[-1]); // 获取刚匹配的字符、加入到
DETECT_RE2C_UNUSED_BEFORE(&ctx->lexer.re2c); // 标记当前字符已处理
goto yy0;
}
<INSTRING,SQUOTE,DQUOTE,BQUOTE,IQUOTE> [^] {
DETECT_RE2C_YYCURSOR(&ctx->lexer.re2c)--;
YYSETSTATE(-1);
RET_DATA_ERROR(ctx);
RET(ctx, TOK_ERROR);
}
那么根据匹配规则。会匹配到 <INSTRING,SQUOTE,DQUOTE,BQUOTE,IQUOTE> .|[\n] 这个接口
这个节点会将1 加入到缓冲区中。然后跳回到初始节点。
4.2.2 处理’
现在已经回到了初始化节点。那么又会走到sqli_INSTRING 这个函数。继续处理INSTRING 那么此刻INSTRING节点就是这几条。匹配规则。则会匹配到
<INSTRING> ['"`] => INITIAL {
YYSETSTATE(-1);
printf("INSTRING\n");
RET_DATA(DATA, ctx, arg);
}
这里就会返回一个内容为1 Token为263 的值。对应的是TOK_DATA
并切换到INITIAL 节点
4.2.3 处理 空格
因为已经到了INITIAL 节点。那么处理空格就到了如下的一个块上去了
<INITIAL> whitespace {
DETECT_RE2C_UNUSED_BEFORE(&ctx->lexer.re2c);
goto sqli_INITIAL;
}
处理完空格后还是在INITIAL 节点中
4.2.4 处理union
因为INITIAL 节点上面有这个union 的token 就返回了291 这里并且设置了SQLI_KEY_INSTR 指令
<INITIAL> 'UNION'/key_end {
printf("UNION\n");
KEYNAME_SET_RET(ctx, arg, UNION, SQLI_KEY_INSTR);
}
4.2.5 处理select
<INITIAL> 'SELECT'/key_end {
KEYNAME_SET_RET(ctx, arg, SELECT, SQLI_KEY_READ|SQLI_KEY_INSTR);
}
4.2.6 处理1
现在还是处于INITIAL 节点匹配到的就是
<INITIAL> '\\'|[0-9] {
printf("NUMBER222\n");
if (ctx->var_start_with_num) {
YYSETCONDITION(sqli_NUMBER_OR_VAR);
detect_buf_init(&ctx->lexer.buf, MINBUFSIZ, 256);
detect_buf_add_char(&ctx->lexer.buf, DETECT_RE2C_YYCURSOR(&ctx->lexer.re2c)[-1]);
goto sqli_NUMBER_OR_VAR;
} else {
YYSETCONDITION(sqli_NUMBER);
detect_buf_init(&ctx->lexer.buf, MINBUFSIZ, 256);
detect_buf_add_char(&ctx->lexer.buf, DETECT_RE2C_YYCURSOR(&ctx->lexer.re2c)[-1]);
goto sqli_NUMBER;
}
}
这里1 已经被写入缓存了
然后跳到了sqli_NUMBER_OR_VAR 那么此刻的值是,
那么就会跳转到
<NUMBER_OR_VAR,NUMBER,DECIMAL,EXP_OR_VAR,EXP> [^] => INITIAL {
DETECT_RE2C_YYCURSOR(&ctx->lexer.re2c)--;
YYSETSTATE(-1);
RET_DATA(NUM, ctx, arg);
}
这里就会返回TOK_NUM 266 并且到INITIAL 这个节点
4.2.7 处理,号
因为已经在INITIAL 节点了 那么,号会跳转到
self = [,\.();=:{}~]; // 所有可能的SQL操作符字符
<INITIAL> self {
printf("SELF\n");
arg->data.value.str = (char *)&selfsyms[DETECT_RE2C_YYCURSOR(&ctx->lexer.re2c)[-1]];
arg->data.value.len = 1;
arg->data.flags = SQLI_KEY_INSTR;
arg->data.tok = DETECT_RE2C_YYCURSOR(&ctx->lexer.re2c)[-1];
RET(ctx, DETECT_RE2C_YYCURSOR(&ctx->lexer.re2c)[-1]);
}
这个节点直接返回ASCII 编码 44
4.2.7 处理2, 同理如上
返回266 和44
4.2.8 处理–
opchar = [!^&|%+\-*/<>];
<INITIAL> opchar => OPERATOR {
printf("OPERATOR\n");
detect_buf_init(&ctx->lexer.buf, MINBUFSIZ, MAXBUFSIZ);
detect_buf_add_char(&ctx->lexer.buf, DETECT_RE2C_YYCURSOR(&ctx->lexer.re2c)[-1]);
goto sqli_OPERATOR;
}
<INITIAL> '-' => MINUS {
detect_buf_init(&ctx->lexer.buf, MINBUFSIZ, MAXBUFSIZ);
detect_buf_add_char(&ctx->lexer.buf, DETECT_RE2C_YYCURSOR(&ctx->lexer.re2c)[-1]);
goto sqli_MINUS;
}
这里有两个匹配的、那个在前面就会走那个。这里会走opchar 的组。下一跳为OPERATOR
<OPERATOR> '-' {
assert(ctx->lexer.buf.data.len > 0);
if (ctx->lexer.buf.data.str[ctx->lexer.buf.data.len - 1] != '-')
goto opchar_generic;
ctx->lexer.buf.data.len--;
YYSETCONDITION(sqli_DASHCOMMENT);
YYSETSTATE(-1);
if (!ctx->lexer.buf.data.len) {
detect_buf_deinit(&ctx->lexer.buf);
goto sqli_DASHCOMMENT;
}
goto operator_done;
}
这里因为不是结尾了。所以会走到DASHCOMMENT
<DASHCOMMENT> [\x00] => INITIAL {
// TODO: create UNCLOSED_COMMENT key
DETECT_RE2C_YYCURSOR(&ctx->lexer.re2c)--;
goto sqli_INITIAL;
}
触发结尾符。然后状态返回INITIAL最后触发结束符
<INITIAL> [\x00]|'-'[\x00]|'/'[\x00] {
printf("INITIAL -");
if (ctx->lexer.re2c.fin && ctx->lexer.re2c.tmp_data_in_use &&
ctx->lexer.re2c.pos >= ctx->lexer.re2c.tmp_data + ctx->lexer.re2c.tmp_data_siz) {
return (0);
}
printf("yy0 -");
goto yy0;
}
这里是没有返回的。
4.2.9 统计
最终得到的Token序列如下
|
值
|
对应的TOK
|
Token 值
|
|
1
|
TOK_DATA
|
263
|
|
UNION
|
TOK_UNION
|
291
|
|
SELECT
|
TOK_SELECT
|
313
|
|
空格
|
无
|
无
|
|
1
|
|
266
|
|
,
|
44
|
44
|
|
2
|
TOK_NUM
|
266
|
|
,
|
44
|
44
|
|
3
|
TOK_NUM
|
266
|
|
,
|
44
|
44
|
|
4
|
TOK_NUM
|
266
|
|
空格
|
无
|
无
|
|
–
|
无
|
无
|
|
–
|
无
|
无
|
整体向语法检测的输出了如下的Token
[DEBUG] 词法单元: 263 [DEBUG] 词法单元: 291 [DEBUG] 词法单元: 313 [DEBUG] 词法单元: 266 [DEBUG] 词法单元: 44 [DEBUG] 词法单元: 266 [DEBUG] 词法单元: 44 [DEBUG] 词法单元: 266 [DEBUG] 词法单元: 44 [DEBUG] 词法单元: 266
五、语法分析
yacc 代码如下
https://github.com/wallarm/libdetection/blob/master/lib/sqli/sqli_parser.y
5.1 LALR(1)算法介绍
这里采用的LALR(1)算法 它属于自下而上的分析方法
这里使用一个示例文法举例子
E -> E + T E -> T T -> T * F T -> F F -> ( E ) F -> id
自下而上分析过程示例
假设输入的符号串是 id + id * id,下面是使用该文法进行自下而上分析(移进 – 归约)的步骤:
| 步骤 | 栈状态 | 输入符号串 | 动作 |
| 1 | $ | id + id * id $ | 移进 id |
| 2 | $ id | + id * id $ | 归约 F -> id |
| 3 | $ F | + id * id $ | 归约 T -> F |
| 4 | $ T | + id * id $ | 归约 E -> T |
| 5 | $ E | + id * id $ | 移进 + |
| 6 | $ E + | id * id $ | 移进 id |
| 7 | $ E + id | * id $ | 归约 F -> id |
| 8 | $ E + F | * id $ | 归约 T -> F |
| 9 | $ E + T | * id $ | 移进 * |
| 10 | $ E + T * | id $ | 移进 id |
| 11 | $ E + T * id | $ | 归约 F -> id |
| 12 | $ E + T * F | $ | 归约 T -> T * F |
| 13 | $ E + T | $ | 归约 E -> E + T |
| 14 | $ E | $ | 接受 |
每个上下文都会有一个初始的状态。
因为在detect_sqli_start 函数中。
static int
detect_sqli_start(struct detect *detect)
{
unsigned i;
// 遍历所有上下文
for (i = 0; i < detect->nctx; i++) {e_new
ctx->pstate = sqli_parser_pstate_new();
sqli_lexer_init(&ctx->lexer);
if (detect_sqli_push_token(ctx, sqli_ctxs[ctx->type].start_tok, NULL) != 0)
break;
}
}
这个为初始的状态。后续的上下文都是从这个初始的状态开启。进行匹配语法的。
还是用用户输入1′ union select 1,2,3,4 — 为例子
ctx->lexer.instring 为true的状态下
[DEBUG] 词法单元: 263 TOK_DATA [DEBUG] 词法单元: 291 TOK_UNION [DEBUG] 词法单元: 313 TOK_SELECT [DEBUG] 词法单元: 266 TOK_NUM [DEBUG] 词法单元: 44 [DEBUG] 词法单元: 266 TOK_NUM [DEBUG] 词法单元: 44 [DEBUG] 词法单元: 266 TOK_NUM [DEBUG] 词法单元: 44 [DEBUG] 词法单元: 266 TOK_NUM
5.2 处理 263 TOK_DATA
data: TOK_DATA
这里就直接返回了。因为解析器需要更多令牌,继续处理
5.3 处理 263 TOK_UNION
在处理TOK_UNION 之前。需要向上去找到TOK_DATA 最顶层的规则(文法)
data_name: data
| TOK_NAME
| TOK_DATA2
| TOK_TABLE
| TOK_BINARY
| TOK_OPEN
| TOK_LANGUAGE
| TOK_PERCENT
| '{'[u1] TOK_NAME[name] noop_expr '}'[u2] {
YYUSE($u1);
$$ = $name;
YYUSE($u2);
}
/* Tokens-as-identifiers here */
;
找到了data_name 为什么找到data_name 因为 可以是由一个单独的data 来代表。那么就可以用这个data_name 继续往上找
colref_exact2 因为data_name 单独表示colref_exact2
colref_exact2:
data_name
通过colref_exact2 继续向上找
colref_exact: colref_exact2
| data_name[dname] ':'[u1] colref_exact2 {
printf("经过 colref_exact21111\n");
sqli_token_data_destructor(&$dname);
YYUSE($u1);
}
;
可以找到colref_exact
noop_expr: expr_common
| logical_expr
| colref_exact{
这里logical_expr 可以单独代表noop_expr 那么就可以继续往上找
expr_cont:
| noop_expr after_exp_cont_op_noexpr after_exp_cont
| noop_expr where_opt after_exp_cont_op_noexpr after_exp_cont
;
处理UNION
union_tk:
TOK_UNION {printf("经过 union_tk\n");}
| TOK_INTERSECT
| TOK_EXCEPT
;
union_c: union_tk[tk] {
printf("经过 union_c\n");
sqli_token_data_destructor(&$tk);
}
;
5.4 处理 313 TOK_SELECT
select: TOK_SELECT[tk] select_args into_opt from_opt
where_opt select_after_where {
sqli_store_data(ctx, &$tk);
}
| TOK_SELECT[tk] select_args from_opt into_opt
where_opt select_after_where {
sqli_store_data(ctx, &$tk);
}
| select union_c all_distinct_opt select_parens
| select union_c all_distinct_opt execute
;
这里因为需要传递参数。所以需要等待用户传递的参数
5.4 处理 266 TOK_NUM
noop_expr: expr_common{ printf("noop_expr->expr_common\n");}
| logical_expr{ printf("noop_expr->logical_expr\n");}
| colref_exact{ printf("noop_expr->colref_exact\n");}
| colref_asterisk{ printf("noop_expr->colref_asterisk\n");}
| TOK_NUM {
printf("noop_expr->TOK_NUM\n");
sqli_token_data_destructor(&$TOK_NUM);
}
| noop_expr post_exprs
;
往上追溯noop_expr
select_arg:
noop_expr alias_opt
;
因为alias_opt 是可以为空的。符合select_arg
那么
TOK_SELECT[tk] select_args from_opt into_opt
这条规则就符合from_opt into_opt where_opt select_after_where 这些都是可以为空的。
那么就成立select 这条规则。
debug 如下
[DEBUG] 词法单元: 263 Value: 1 TOK_DATA [DEBUG] 词法单元: 291 Value: UNION 经过 colref_exact2 sqli_token_data_destructor Value: 1 经过 colref_exact: colref_exact2 noop_expr->colref_exact 11dada 经过 union_tk 经过 union_c sqli_token_data_destructor Value: UNION [DEBUG] 词法单元: 313 Value: SELECT [DEBUG] 词法单元: 266 Value: 1 noop_expr->TOK_NUM sqli_token_data_destructor Value: 1 [DEBUG] 词法单元: 44 Value: , select_arg->noop_expr 经过 select_list [DEBUG] 词法单元: 266 Value: 1 noop_expr->TOK_NUM sqli_token_data_destructor Value: 1 select_arg->noop_expr 经过 27222 经过 select2 sqli_store_data: unknown token 313 sqli_store_key1: READ sqli_store_key2: SELECT detect_ctx_result_store_token1: READ sqli_store_key1: INSTR sqli_store_key2: SELECT detect_ctx_result_store_token1: INSTR sqli_token_data_destructor Value: SELECT ---------------------------end----------------
六、总结
1. 这个思路可以参考,实际应用当中会有很大的误报需要进行调整词法分析和语法分析
2. 性能较弱
3. 需要增加打分选项
4. 规约冲突 移进冲突较多、需要细化

