python 2 or 3 的字符编码转换

字符编码与转码
http://www.cnblogs.com/yuanchenqi/articles/5956943.html
http://www.diveintopython3.net/strings.html
需知:
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
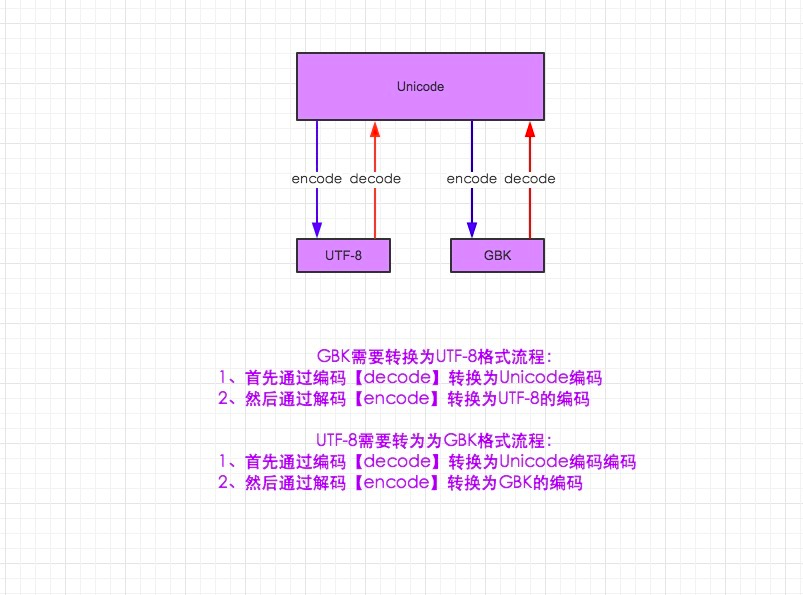
上图仅适用于py2
在python2 中尝试一下
# -*- coding: utf-8 -*- s="你好" print(s) python2 打印默认编码: [root@liang ~]# cat b.py #-*- coding:utf-8 -*- import sys print(sys.getdefaultencoding()) [root@liang ~]# python b.py ascii
从utf-8 转换到gbk
#s_to_gbk=s.docode("utf-8").encode("gbk")
# -*- coding: utf-8 -*-
s="你好"
s_to_gbk=s.decode("utf-8").encode("gbk")
print(s_to_gbk)
gbk转为utf-8
# -*- coding: utf-8 -*-
s="你好"
s_to_gbk=s.decode("utf-8").encode("gbk")
print(s_to_gbk)
gbk_to_utf8=s_to_gbk.decode("gbk").encode("utf-8")
print(gbk_to_utf8)
在python3 中 默认是unicode 的模式。所以只需要encode(“gbk”)
s="你好"
s=s.encode("gbk")
print(s)


1
2018年5月5日 下午7:57
1